The almost genius playlist from 3blue1brown.
vector
has a mathematically rigorous definition, but for computer science, treat it as a column or a row of numbers. Each number represents a scalar along a dimension, ordered by your basis.
So in , .
the origin is fixed of course at , and this holds for any coordinate system as long as we are not translating the origin.
basis
What is the direction and scale of “1 unit”, as I choose to define it? Default is just to use orthogonal , , and in the default grid sense.
linearity
addition
means steps in the direction and then steps in the direction.
.
scalar
means multiply length by , in the same direction.
These two conditions make linearity. Formally, for a transformation :
A visual test is that an evenly spaced line of points remains evenly spaced after .
note that origin will remain fixed
span
Defined in terms of and .
.
What surface do the possible ends draw?
matrices
Say I want to define a transformation on and :
The columns represent the new positions of and after the transform.
The effect can be a shear, scale, rotation, etc.
What would my original vector look like? is the final position of the end.
You can think like this: if my is now , I move double the steps. If my is rotated, I do the same on .
What is interesting is:
.
After the transform, the same scalars still hold:
.
For example, if , then .
And if you forget “vectors” and treat it like matrix multiplication, the effect is constructed to be the same.
linear independence
Defined for a set of vectors.
You can ask: does it add anything to the span? If the span remains the same even if I remove it, then it can be constructed by some linear combination of the remaining vectors.
That is, , so it is linearly dependent.
basis
Defined for a space, say or .
It is the linearly independent set of vectors that span it.
dimension collapse
Say I use a transformation where is linearly dependent on .
A trivial one is same as :
So the second dimension is gone: for every input, .
The span, which for a basis was a plane, is just a line after transformation. Note that this is not a basis change; we still describe scalars in terms of and .
Think of it as one-way loss of information. I cannot uniquely go back from something on the line to what was before the transformation. Just like , I have no way to know what could have been, except “anything”.
compositions
A transformation can be a scale, shear, rotation, reflection, projection, or a composition.
In general, .
To read it, go right to left: .
determinant
Under a transformation , area in 2D, or volume in higher dimensions, scales by .
Negative determinant implies orientation flip.
Think of a dimension collapse from some area in 2D to a line with 0 area. This is what it means to have a collapse when .
For higher dimensions, collapse can be in multiple dimensions. Say and collapse to 0, so you have a line as span, or all collapse to 0, so just a point remains as span.
Now if you think of it as area or volume scaling, then clearly:
.
Visually, then is the same as in compositions.
linear system of equations
The good case has equations and variables. Say we have 2:
.
Think of as the vector that I want to find. Then is a transformation defined by constants, and is the resultant vector.
So a linear equation is: what transformation applied to makes it the same as ?
The inverse reverses the transform:
.
Except, if collapses everything to a lower dimension, , then we can never say for sure what the original was.
If , there are infinite solutions. If , there is no solution.
rank
.
If the transform collapses dimensions, rank decreases.
Say rank decreases by . If , then a whole plane has collapsed to a point.
column space
Of a transform , the column space is:
.
There must be some redundancy / linear dependence in the columns to collapse dimensions.
null space/kernel
Say dimensions do collapse. Then the set of vectors that got collapsed to 0 is the null space:
.
non-square matrices
It is very much possible to apply a transformation that changes dimensions:
.
I can define a linear transform as projection onto the x-axis:
Any higher-to-lower dimension transform cannot be reversed uniquely: is not one-to-one.
What as a transform shows:
dual
A dual vector is a linear transform to a scalar:
.
For a column vector in , the dual is a row of elements. The operation is just matrix multiplication to a scalar:
The idea of a dual is that it lets you define, for say 2D, , which can extract info from the vector as a linear map.
Take dot product with another vector . Then . The transform is tied to here; it gives a signed scalar measurement along .
I feel the idea is pretty redundant
dot product
For , the dot product is:
.
The scalar that it gives is the dot product.
Now .
Why? Assume both are the same length. You can make a line bisecting the angle between them. In such a scenario, both and are interchangeable.
Now if and have different lengths, consider , such that and are the same length as above.
You get the same symmetry, with the extra factor put back. The idea visually explains dot product commutativity.
Now you can use the above dual idea to define dot as well.
Instead of dot of 2 vectors, define dot as a dual tied to one vector and applied to the other:
.
again a bit redundant idea unless we build on top
cross product
Geometrically, is the area of the parallelogram enclosed by and .
Though it is defined as a vector being the result.
In such a scenario you can technically say that cross product is not defined in 2 dimensions as a vector in the same space, since the result needs to be perpendicular and there is no space in 2 dimensions.
In 3D, it gives a perpendicular vector with magnitude equal to the area. Which orientation is then convention.
some intuition on the calculations
You can think of as giving an area-oriented vector.
If you dot another vector with it, it gives the volume of the 3 vectors :
.
Now say I want to find that perpendicular vector and I have and .
I can define a 3D to 1D transform as:
.
Magnitude wise, this determinant is the same as dot of and the cross product :
, where .
Now if you dot and compare coefficients:
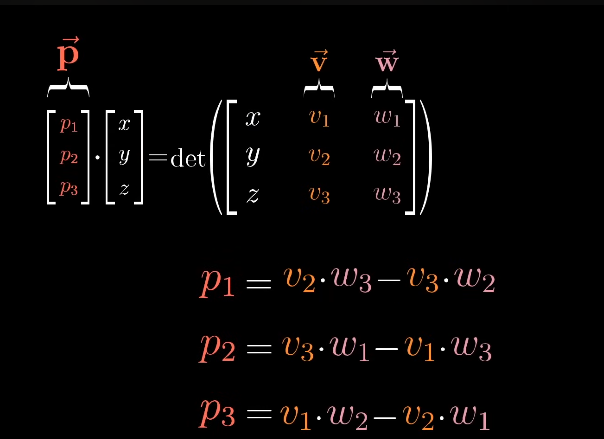
and compare coefficients, you get the actual cross product.
cramer’s rule
the good case
Say we have 2 equations and 2 unknowns:
.
is a transform.
Geometrically it is: what transform do I apply on to make it the same as ?
Now you can take an inverse and so on.
But there is a different argument too.
Initially I have .
Say I want to find the x-coordinate.
Area of and :
.
Area after transform: , and , so area is now .
But this area must have been scaled by :
.
So:
.
change of basis
When we apply a transform on that doubles , the resulting vector is in the x direction because our basis is still the same.
Basis is how we define our vector relative to.
Had I scaled my basis, , then my vector would be the same.
A vector is just scalars saying move units in basis 1 direction, then units in basis 2 direction, and so on:
.
Denote as the change-of-basis matrix. For a transform , this is a bit reverse.
If and is defined in their basis, then:
.
So the effective transform in mine is:
.
eigenvectors and eigenvalues
Under any transform , there may exist certain vectors that only change in scale:
.
Such vectors are called eigenvectors, and the scale change is the eigenvalue. So eigenvectors and eigenvalues are closely paired.
Move everything to one side:
.
So:
.
For this to have a nonzero solution, the determinant must be 0:
.
Once you get , substitute and solve .
Exclude .
The span of the eigenvectors is the eigenspan. If that eigenspan also spans the current space, you can choose an eigenbasis from it.
Under eigenbasis, each component of the basis is transformed separately by simple scaling by eigenvalue.
So if it exists, the transform would just be a diagonal matrix with eigenvalues on the diagonal.
This is called diagonalisation.
Say I want to calculate now. Under eigenbasis, that is cheap:
.
You can combine that with change of basis:
.
abstracting out the geometry
You can think of “axioms” as an interface. I define some constraints, here linearity:
and .
If whatever you have follows that, you can do all sorts of things on that.
For example, polynomials and derivatives can fit into the same linearity framework.
It will not be possible to visualise polynomials just as easily as lines and planes, but everything still holds. This is abstracting out the geometry.